What I have been doing the last years has nothing to do with classic media production anymore. In the past, I was used to creating style sheets, aligning boxes and refining typography in a layout application. Countless times I exported print PDFs and checked everything thoroughly again afterwards. Mostly until I found at least one error. That’s over now: when I do media production today, I put fields and content into content management systems and develop intelligent HTML templates to output this content – not only on the web. In this world, design is an algorithm that needs to be defined. And publishing is a process that is modeled in the same way as the many other processes in a company. It all sounds suspiciously like IT, and that’s exactly what it is: publishing, media production, design, marketing – all IT.
This is nothing new! Some people may now cry out: Publishing has always been IT! Right, but IT today is also something different than it used to be. Where the desktop computer with installed applications used to dominate, and where the actual computing work was happening, today a different picture emerges: More and more we open the browser and open an application in it, which is operated locally, but is actually executed and calculated on some remote server. The speed at which more and more applications are moving from the desktop to the browser is breathtaking. And also, many desktop applications are completely or partially just windows to remote servers where the real work is done. These remote servers are often called clouds. If only this term wasn’t so terribly familiar and boring!
Unfortunately, Adobe has made us publishers particularly disgusted by the word "cloud" by simply renting out the well-known applications and at the same time writing “cloud” on them. Annoying, because cloud is so much more.
Over four years ago I wrote in an article: “the pure storage of data (whether in the cloud or locally) is not very sexy, the intelligence of the infrastructure is central – so what can be done with this data. And that’s where Adobe only scratches the surface of the possibilities”. In the same text, I continued speculating about an “operating system for the cloud”. Now that I am a few years older, have become wiser in some areas and have been able to learn new things in many projects, I believe I can turn the old speculation into a certainty. The operating system has been found. With one crucial semantic difference: there is no need for an operating system for the cloud, the cloud is the operating system. And all, really all that the cloud needs to function is – drum roll – URLs!
Really? Again, such a familiar, somehow also boring term. Maybe the most exciting thing about the cloud is that we have known many of the concepts behind it for a long time. What’s new is that the pieces of the puzzle are now coming together. That URLs, APIs, Webhooks, browsers, HTML and many other concepts, which for some of us are still to be discovered, now fit together to form a coherent overall picture. All of this can be seen in tools, which in turn, connected to each other, create a publishing world that is more flexible, dynamic, extensible and, yes, even simpler than what was there before. While the Creative Cloud may have been the operating system of traditional publishing, the new operating system consists of URLs, Webhooks and APIs.
Sounds cryptic? Okay, let’s make it real:
First, colorful pictures
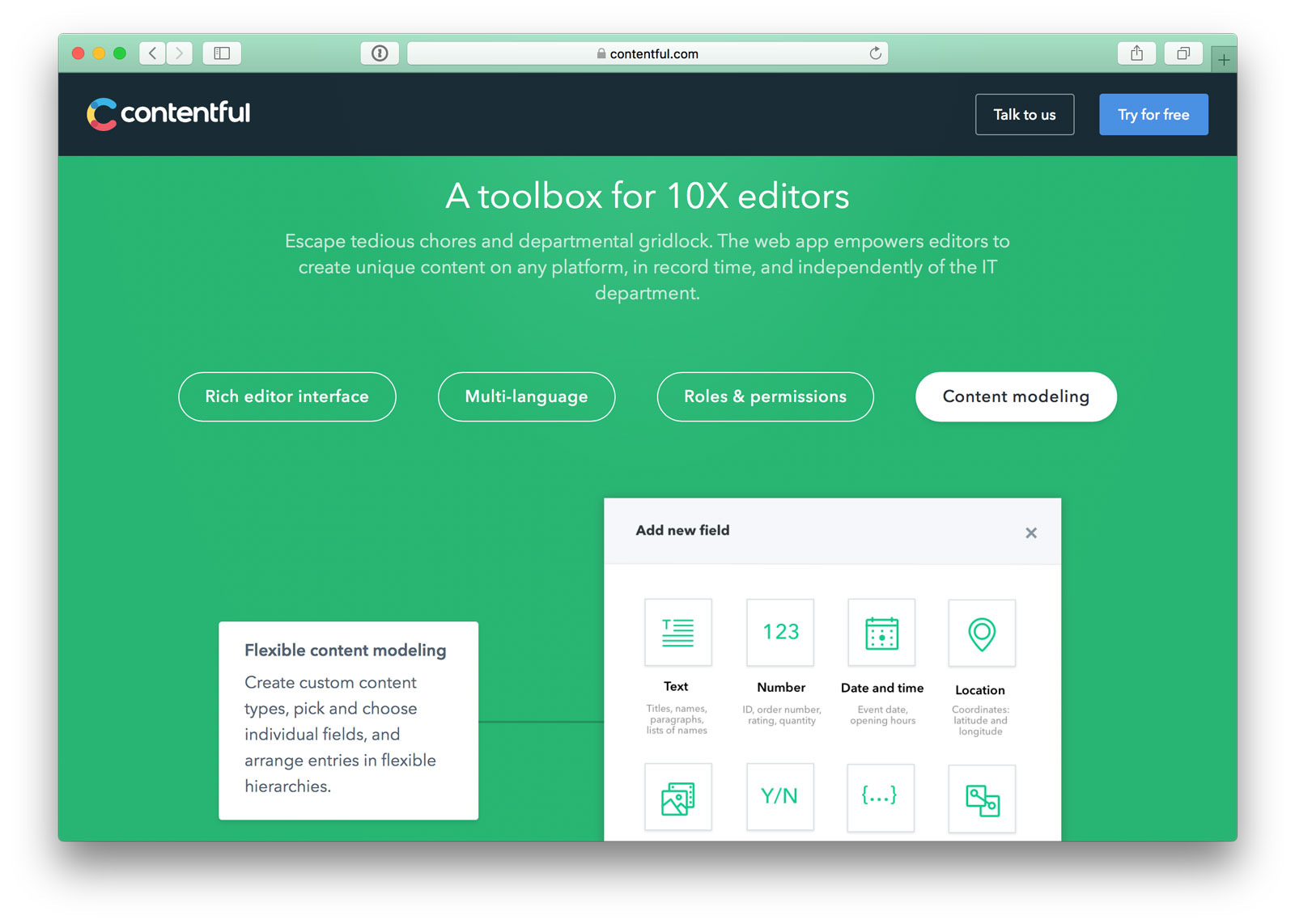
Of course, the story of the new publishing operating system in the cloud must begin with the content. What else? I’ll get to the first association, the texts, in a moment. With images, also weighty content, it’s easier to get started. Up to now, we have saved images on the file server, retouched them with Photoshop, altered them, composed them and saved them again. What would be gained if the image was stored in the cloud instead of on the local file server? Nothing at first. Well, the image would have a URL: www.mycloud.com/image.jpg. Yawning again. But wake up, now it’s getting exciting: Couldn’t we do something like this with it: www.mycloud.com/width_300,height_300/image.jpg? We simply write in the URL how we would like to have the picture, 300 pixels wide, 300 pixels high. Voilà, there we have the picture, cropped in the desired size. However, this does not look good yet, the faces are cut off. So next try: www.mycloud.com/width_300,height_300,focus_faces/image.jpg. Much better!
The just as stupid and profanely ridiculed URL suddenly becomes a window into a whole new world. What other commands might be hidden? And how does the magic work? When we call the URL, on the server, hidden in the shadows, an application runs, which evaluates the address, builds commands out if it, and executes them. The URL therefore is an interface to a computer program. This interface is what you call Application Programming Interface, short API. A combination of letters that, and I have been saying this for quite some years, everyone in publishing should know. If we now enter www.mycloud.com/width_300,height_300,focus_faces/picture.jpg into the browser, our image cloud first performs a face recognition (this sounds fancier than it is), sets the faces as focus point of the image, cuts a square around them and finally down samples the image to 300 pixels.
Image editing via URL: left the original image in the cloud, in the middle the version with 300 pixels crop to the square and right finally the crop with previous face detection for the focus point. Pay attention not only to the image, but also to the URL, that’s where the magic is happening.
Such cloud services for pictures (and videos) really do exist, they are no invention of mine. Cloudinary is my favorite example, imgix is another one. Services that make images manipulable via URL parameters, with possibilities that go far beyond the simple example here. Don’t you think so? So, let’s build a more complex workflow.
A true print bolide
Which of the old print wizards among our esteemed readers still knows Enfocus Switch? Of course, a still fascinating tool. Files are moved from folder to folder, and in between, connected programs execute commands on these files. By the way – and I’ll say it so often until it gets annoying – these are APIs, too. Switch is the proven workhorse in the PDF workflows of countless printers and prepress companies. But Switch can do so much more. Because Switch can also communicate with URLs, it’s quickly becoming part of our cloud operating system.
We take an input hotfolder in Switch and place our images in it. Switch takes these images and sends them to a URL. This is again an API, but a slightly different one: Not as the one above, from which I passively demanded something (technically: GET request), but one, to which I myself actively send data (technically: POST request). The API is again nothing else than a URL à la www.mycloud.com/here-new-pictures, to which we will send our pictures which it then processes from there. The application on the server takes our pictures and places them at Cloudinary. With these two types of API URLs – a GET request, which gives us something, and a POST request, to which we deliver something – we can build everything what we have in mind for cloud applications.
Pretty cool, we connected our internal world with that of the cloud and stored our images via Switch at Cloudinary. But it gets even better, because the new images at Cloudinary trigger the next process. We read the metadata (like EXIF or XMP) within an image and get access to the copyright information of the file. If we also know that Cloudinary can also put text and watermarks on images, we can do the following (here written in exemplary pseudo programming code):
If (image has copyright) {
save mycloud.com/square image with watermark and copyright info/image.jpg
}
We send this finished image via URL back to Switch (POST-Request), where it is stored on our file server. So, we just built a process that takes new images, loads them into the cloud, evaluates copyright data in the image, creates a square image with a copyright line – for social media, for example – and finally stores it again in our file server. All done with URLs that talk to each other. WTF.
Data in fields
Let’s tighten the screws further. Copyright information in images, that is metadata, that is data about data. They are extremely important, and their role in the process can hardly be overestimated – especially when we look at new media channels like Alexa and Siri. But the big brothers of metadata, data, are of course even more important: We have already integrated images and videos in the cloud operating system, but text in all its facets is still missing.
Oh, text! For quite some time, we media production fellas have done him more than wrong. We dumped it into bulky, vast rich text editors and even built whole pages in them – just like in Word. Complete websites became stupid “blobs”. A single yeast of text, images and formatting. Nothing to use for, but the beautiful design that we are just making. Even text in a box in InDesign is such a stupid blob, by the way.
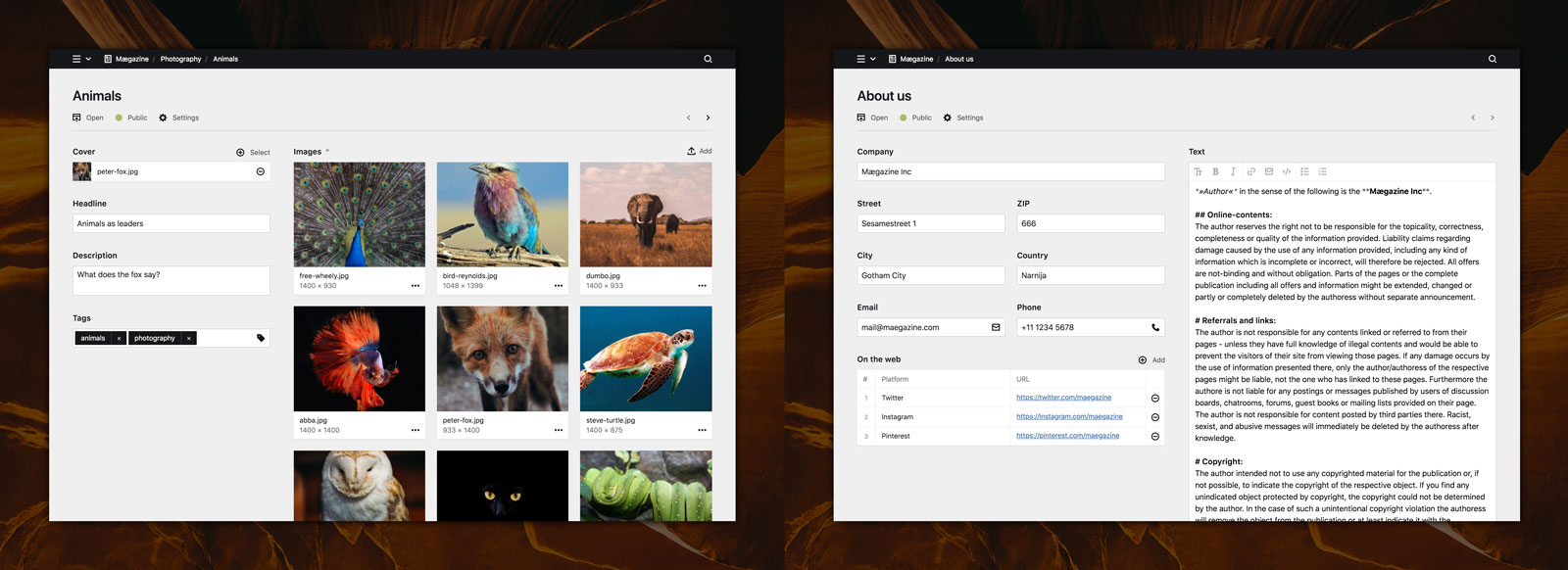
Fortunately, the market has moved on. The blobs can be turned into “chunks” – content broken down into semantically understandable information atoms, which are not stupidly thrown to the page, but intelligently packaged in sets of rules. This has even led to the development of a discipline of its own: content engineering. This meaningful content is perfect for our publishing cloud. But it gets even better. There are systems that make it all affordable and accessible. Of course, WordPress, Gutenberg editor or not, can also be used in this way. But I think systems that are designed for exactly that are better. Kirby is one such system and currently my favorite. Contentful is another – and there are many more.
Both systems are developed (partly) in Germany: Contentful is something more pointedly positioned for enterprise content management in the cloud age, while Kirby can also work for pretty regular websites. The principle is the same for both: You define the fields (Chunks!), from which the content draws its meaning, and receives a tailor-made editing interface, to fill in these fields. These interfaces can be flexibly adjusted to the excess. The is fun, for the software developer, because the systems are designed exactly for these adjustments, and for the content creators, because the interfaces are not looking like Windows 95 and adopt to the content, not vice versa.
Contentful is super flexible and can be adapted to the structure of the content. The Cloud CMS is marketed via a monthly rental fee.
Approval and collaborations processes – in some companies more complicated than the organization chart – can also be implemented in the same spirit. Kirby can do this in an integrated way, while Contentful requires other services such as Zapier or IFTTT. In my view, Kirby in particular shines here. You can tell that a concept works if it can be scaled from the simplest application to a highly complex enterprise application without any disruption. Once the content is entered into all those nice interfaces, the inevitable happens again, we put an API on top! And now every content has not only its representation as a usable, intelligent data format like JSON or XML, but also an URL. For example, www.mycloud cms.com/products could return all product data. Cool, then you can start tinkering with cloud workflows again.
Backend interface in Kirby: The most perfect thing is that you can’t actually show it – the masks for displaying the contents are limited in their flexibility only by your own imagination.
At this point, the reader might get a bit dizzy about the number of systems involved and talking to each other (and I’m not done yet!). Wouldn’t it be easier to find a system that can integrate everything? Sure, but something has changed there as well. While IT used to be dominated by the monolith, the omnipotent, highly bred monster system that supposedly could do everything, today people like to play “Best of Breed”. The best of their breed, that sounds a lot like Social Darwinism, but in reality, it is pure nature romanticism. What could be more beautiful than a colorful, diverse environment? It’s the same with software – of course Kirby could also take care of the image conversions, but Cloudinary was built exactly for this and can do it better. Best of Breed is the IT strategy for the cloud age: you look for the best system for each task, and this system then takes care of exactly this one task, solves it easily and perfectly – and communicates with the other systems via APIs and URLs.
We want to see some design!
In the end, publishing is always about the “thing” that is to be looked at, read, heard, or whatever. We need a frontend, no matter for which channel. Let’s connect the next APIs to our cloud operating system. Which channel would you like?
I often differentiate between two approaches in the setup of the front end: Do we design a medium that can be completely cast in sets of rules, i.e., that can be produced completely automatically? Or are we doing something that we have to work on again, regardless of the quality of the set of rules, and intervene creatively? There are tried and tested tools for both. The mechanics always remain the same – we let URLs talk to each other: For example, we have great content in our CMS, we save it, it is published. In a modern CMS such as Kirby or Contentful, this release event triggers something that we can use as a starting point for the next steps – in programming this is called a hook. Whenever a new release is issued in the CMS, it sends a signal, a “web-hook” (actually just a POST request) to another system. This other system receives the signal and does something with it.
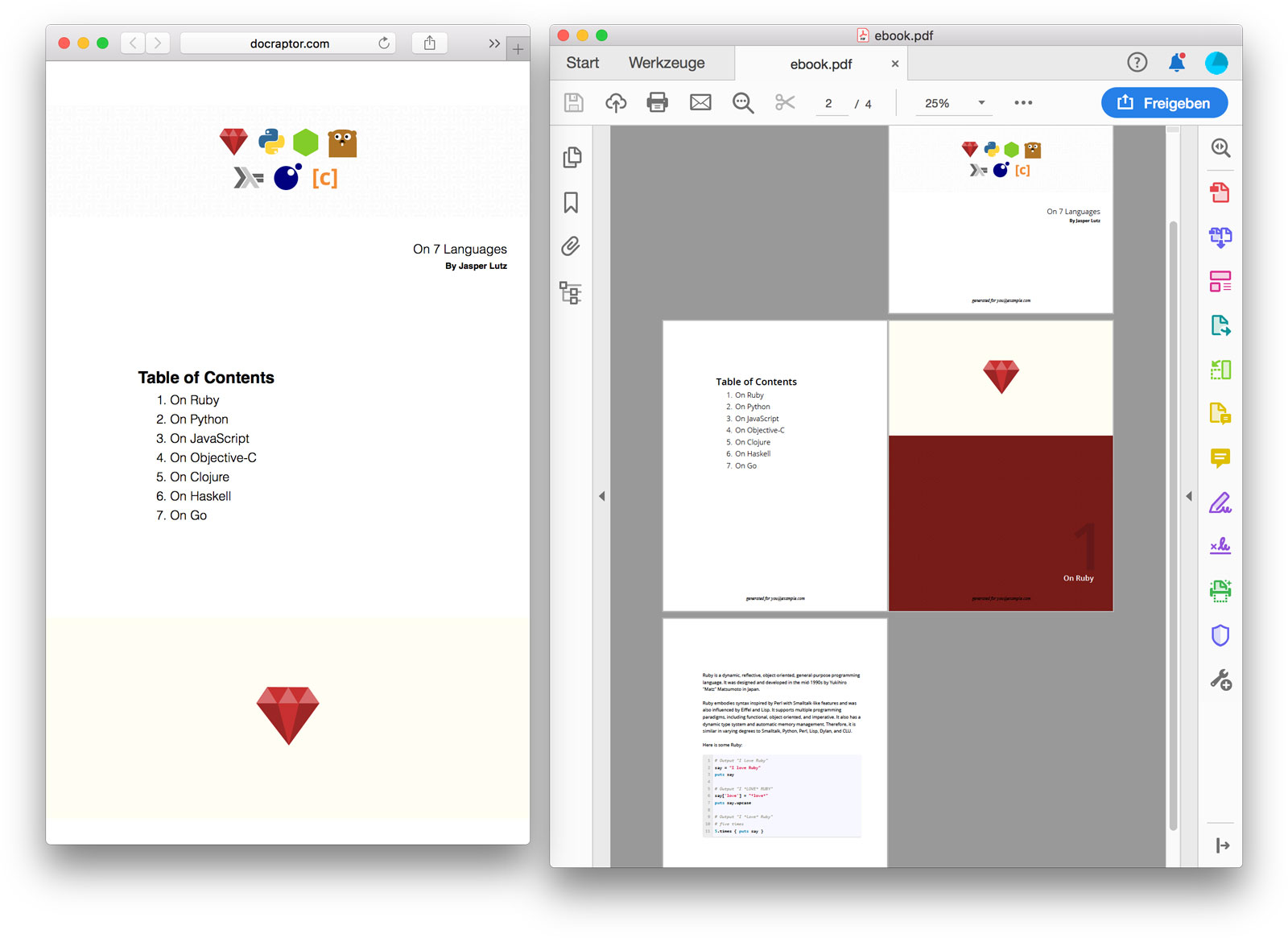
Here is an example of automated print production: Approval is given in Kirby. → Hook “Content XX approved” goes to DocRaptor, a system for creating print PDFs in the cloud. → DocRaptor gets the information about Content XX from Kirby’s API. → DocRaptor feeds the retrieved content into a prepared HTML template (e.g., for a data sheet) and produces a print PDF from it. → This event causes DocRaptor to send a hook to Kirby: “New PDF of content XX.” → Kirby fetches the PDF and saves it in a special field in the CMS. Et voilà, a ready-to-use round-trip workflow from changed content to an always up-to-date data sheet. DocRaptor is an example of a service that implements high-quality, print-ready design in HTML templates based on new CSS specifications. There is even more. The technology is already far advanced here, although there are of course still a few areas, especially in typography, where InDesign and Co. have an advantage – however, in many cases a remedy is already in the works or can be integrated via JavaScript libraries. Let’s predict something: It will probably soon be quite normal to create print products in this way.
HTML becomes print: DocRaptor allows you to create printable PDFs based on modern CSS specifications. This works quite well and will significantly change the role of the classic layout program.
With this workflow, everything runs automatically. It is perfectly suited to all products that can be described in sets of rules, such as data sheets or advertisements. But there are enough products where this is not (yet?) so easy. Do the following – and hopefully the readers head will start spinning: Replace DocRaptor with Switch and HTML with InDesign in the event chain above. Yes! Wicked! It works the same way. Switch can receive the hook from Kirby and process it in an InDesign script. As a small side note, this is another advantage of Best of Breed: The systems are easier to replace when the requirements change.
An InDesign script can work in exactly the same way as DocRaptor does on the HTML level, i.e., it can retrieve the data from the API and feed it into a template based on rules. InDesign scripts unfortunately cannot “out of the box” communicate with URL based APIs. Fortunately, Germany’s InDesign scripter Gregor Fellenz has found a solution with Restix. Using InDesign to typeset solves the problems that may currently still exist with HTML templates – and of course it opens a new world: that of manual intervention in the document. I like to speak of “curating” a medium. The script/template produces a good pre-layout, then it’s up to the human being to bring individuality and creativity into the final product. Is “the best of both worlds” too ordinary a phrase for that? Anyway, it’s true and should reassure everyone who thinks APIs and CMS fields for screw catalogs are quite nice, but for more please don’t do it. The finished product can be put back into the CMS via switch and a casual POST-request, or, if you like it, it can be entered manually.
The same approach of automatic and curated media can be transferred to the web. If the whole frontend can be packed into a set of rules, static page generators or JavaScript frameworks like Vue or React are the order of the day. Of course, these systems get the content from the CMS-API, from Cloudinary or from wherever and let it flow into templates with output logic. If that doesn’t work and the website has to be refined with manual human intervention, similar to a printed collateral, I like to use a method that seems strange at first: I set up a second CMS, one for the frontend. Amazingly, this second CMS retrieves the API data, places it in the page tree and gives the “curator” certain design options and extensions. Yes, that works quite well! It’s actually the same as above with InDesign. A celebration for all theorists and practitioners of the separation of media neutrality and media specificity – if you have any questions, ask.
Now let’s take a quick look at some channels in a quick walkthrough. A newsletter with Mailchimp? Mailchimp has an API. An app can query APIs. A chat bot also talks to your API. A search engine like Algolia? API ... A translation management system? In and out via the API. A social media plan? Hootsuite API to the Rescue. An Alexa-Skill? I think you have understood the idea...
A command line for the cloud
All right, dear reader? I have one more for you! All this back and forth from GET and POST requests, from queries, hooks and outputs is quite fancy, but somehow, it’s a bit uncontrolled. Well, somebody came up with the whole thing and made it happen. But let’s face it: One click in one system has a thousand sequels in different other systems – and nobody notices anything? That’s just not possible. Fortunately, there’s Slack, or Stackfield, or Microsoft Teams, or any of the other WhatsApp-style enterprise chat tools. Not only do these programs replace email, they also have APIs. And that puts us right back in the middle of the fun:
A new image, for example, which is uploaded via a Switch to Cloudinary, triggers a “new image” event there. We now go back to this event and send a request to Slack: “Look here, a new image.” Slack picks up the signal and sends an info about the new picture to everyone who is interested (and a few more people to be sure) in the chat channel. Or: A new content is released in Kirby – hook, POST request, bam, everybody knows about it in Slack. Same game when a content expires. Whenever something happens, we see it in the chat window. It’s so frighteningly simple that it almost hurts. Without any major twists and without any new technical means, we have added a veritable notification layer to our already great cloud workflows. I am always amazed how much a process looks like “software” when it suddenly communicates its status in Slack.
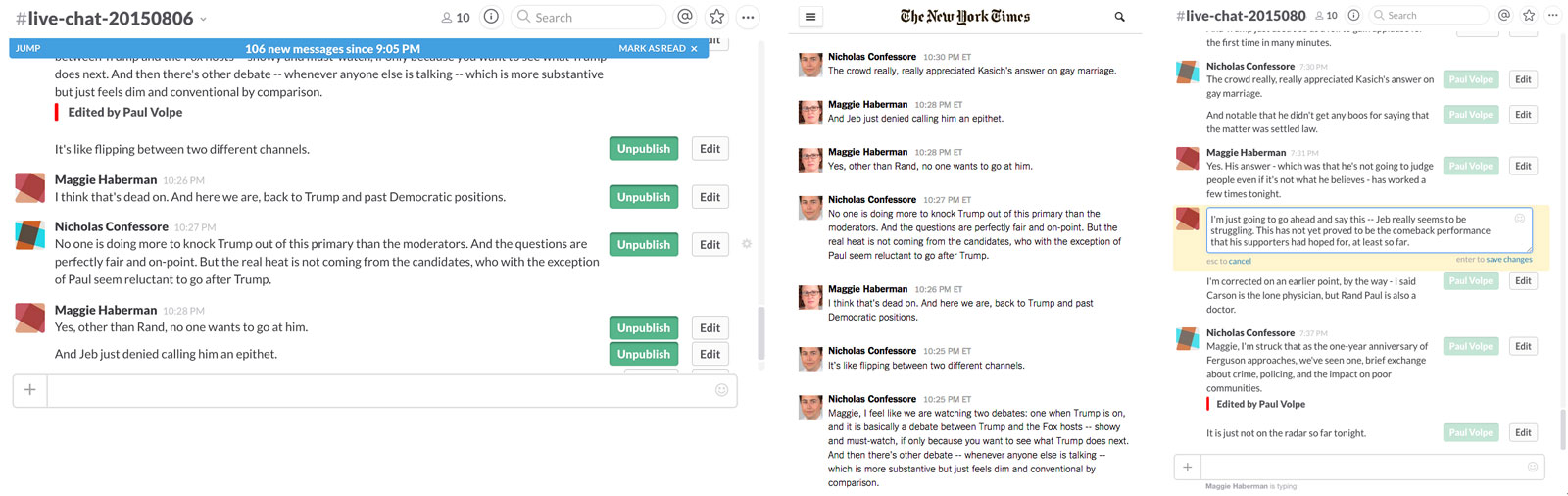
Time for the last stage. Now it becomes really extreme. How about if Slack could not only “report” something in his chat line, but if we could also send commands into the cloud via the chat? Yeah, that would be cool. And of course, we could do that, too. Even though this example is a bit older, it’s still brilliant: The “New York Times” has built a mini-editing system with an approval and correction workflow in Slack. Publishing in chat, built for the Republicans’ (!) presidential debate. For the live blog the reporters’ “slack” cheerfully. An editor reads the news in Slack, edits it a little bit if necessary and finally presses the (added) publish button. Snap! Slack sends a request to the publishing system: “Here, a new content.” And the publishing process begins. What possibilities this opens up! We can request the new image we are informed about directly from Slack in different variants of Cloudinary. The article that expires tomorrow can be renewed using a new date in the chat line ...
Even if this example is a bit older, it is still ingenious: The “New York Times” has built a mini-editorial system with approval and correction workflows in Slack. Publishing in chat.
Or, thinking about it, what about this workflow: The chat asks us step by step for the fields of our content chunks, we write the answers into the input slot, when everything is ready, we give the release to the CMS from the chat and then we get finished data sheets, social media posts or whatever posted in the Slack. OMG.
Is there perhaps a cloud publishing operating system after all? Is it the chat? Or is it, like the classic command line, more of an anachronism that you soon can’t live without? Or is the chat in the end just a component in our concert of APIs, URLs, hooks, requests and templates, which we can easily exchange Best of Breed-style? I don’t really care, that’s too philosophical for me. I’d be satisfied if your brain was smoking now and the first GET and POST requests chase back and forth between the synapses.
The German original of this article appeared first in the Swiss magazine “Publisher” with the headline “Die Wolken verbinden”.
I’m one of those guys in the media production and publishing scene, that is often labeled as a thought leader. But I’m a practitioner. Day in and day out I work as Head of Crossmedia Production in an advertising agency. I’m hands on creating content infrastructures and designing websites, apps and social media stuff that are driven by these infrastrucutures. This it what grounds me. And it is this daily business work that helps me identifying the trends and emerging topics of our field. With that kind of real world knowledge, I’m an active participant in bringing our industry forward: I write a lot about agile publishing, digital publishing, development, and media production, not just here but also in well know magazines and journals. I’m a keynote speaker at conferences and do a lot of trainings and consulting work. Since I’m originally a print person, I was involved in developing industry guidelines for PDFX-ready. I co-authored the book “Agile Publishing”, still the 400 pages reference work on how agile processes move user experience and storytelling in the spotlight of todays multichannel world. I’m living at the intersection of design, content, technology and marketing. How hypes can be moved into practical use is what drives me every day.
www.xing.com/profile/Georg_Obermayr www.linkedin.com/in/georgobermayr www.twitter.com/georgobermayr Buy the book "Agile Publishing" on Amazon